Параллельная реализация локального ансамблевого фильтра Калмана …
7
имеет 128 ядер (1664 процессорных ядра Intel Itanium 2 9140М, опе-
ративная память 6,6 TB) пиковой производительностью 11 Тфлопс.
Расчеты производились для следующих значений числа процес-
сов: 4, 8, 16, 32 и 64 (степени двойки), 40, 80, 160 (распределение
примерно равного числа широтных полос между процессами).
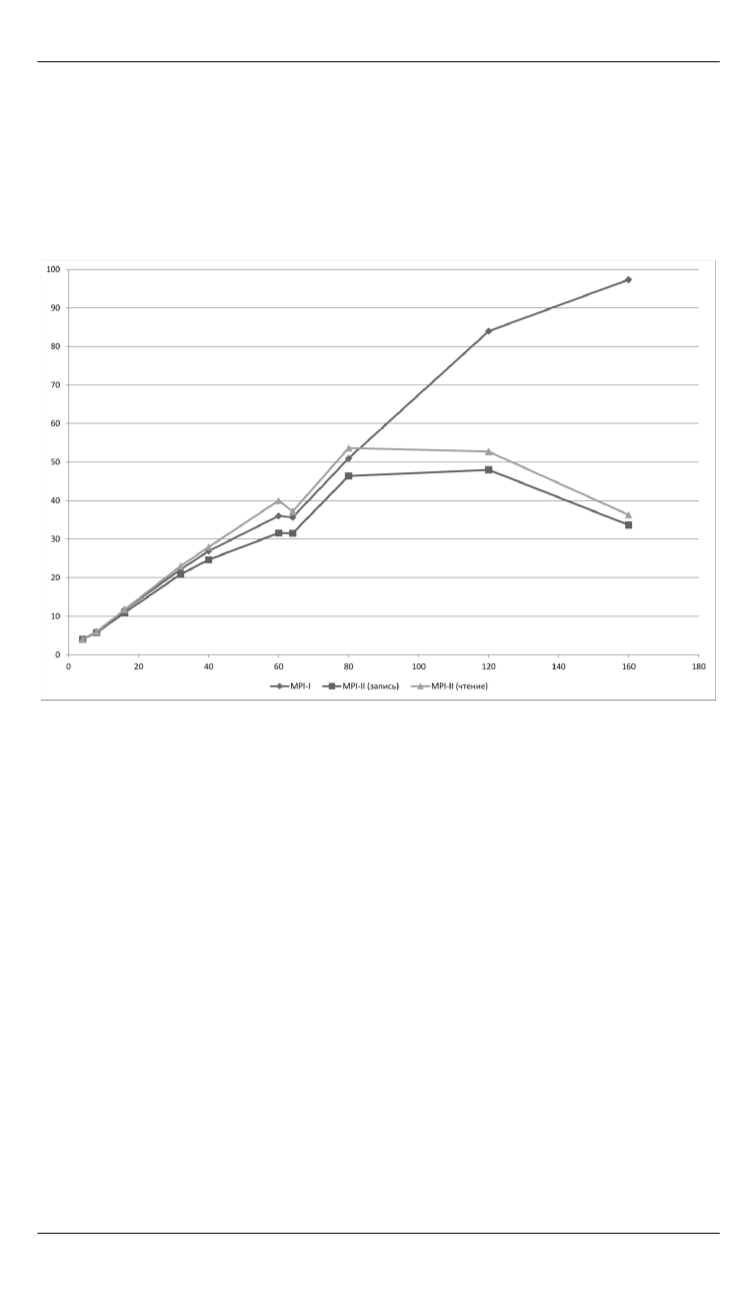
График параллельного ускорения расчетов представлен на рис. 1.
Рис. 1.
Ускорение при использовании 60 членов ансамбля
Из графиков видно, что рост ускорения близок к линейному для
60 участников ансамбля. На рис. 2 приведена эффективность парал-
лельной реализации при использовании MPI-I для 60 участников ан-
самбля.
Видно, что эффективность уменьшается с увеличением числа
процессов. Это объясняется тем, что неравномерностью распределе-
ния вычислений между процессами. C точки зрения количества обра-
батываемых узлов сетки данные распределяются равномерно, при
этом вычислительная сложность задачи зависит от числа обрабаты-
ваемых локальных (расположенных на расстоянии не больше задан-
ного) наблюдений. Наблюдения распределены неравномерно, кроме
того, широтные полосы в областях, расположенных у полюсов, по-
крывают меньшую площадь, чем широтные полосы в областях,
ближних к экватору.
Таким образом, бо́
льшая часть вычислительных процессов ожида-
ет вычисления анализа процессами, на которые за счет бо́
льших пло-
щади и числа наблюдений приходится бо́
льшая нагрузка. Распределе-


