Б.А. Князев
12
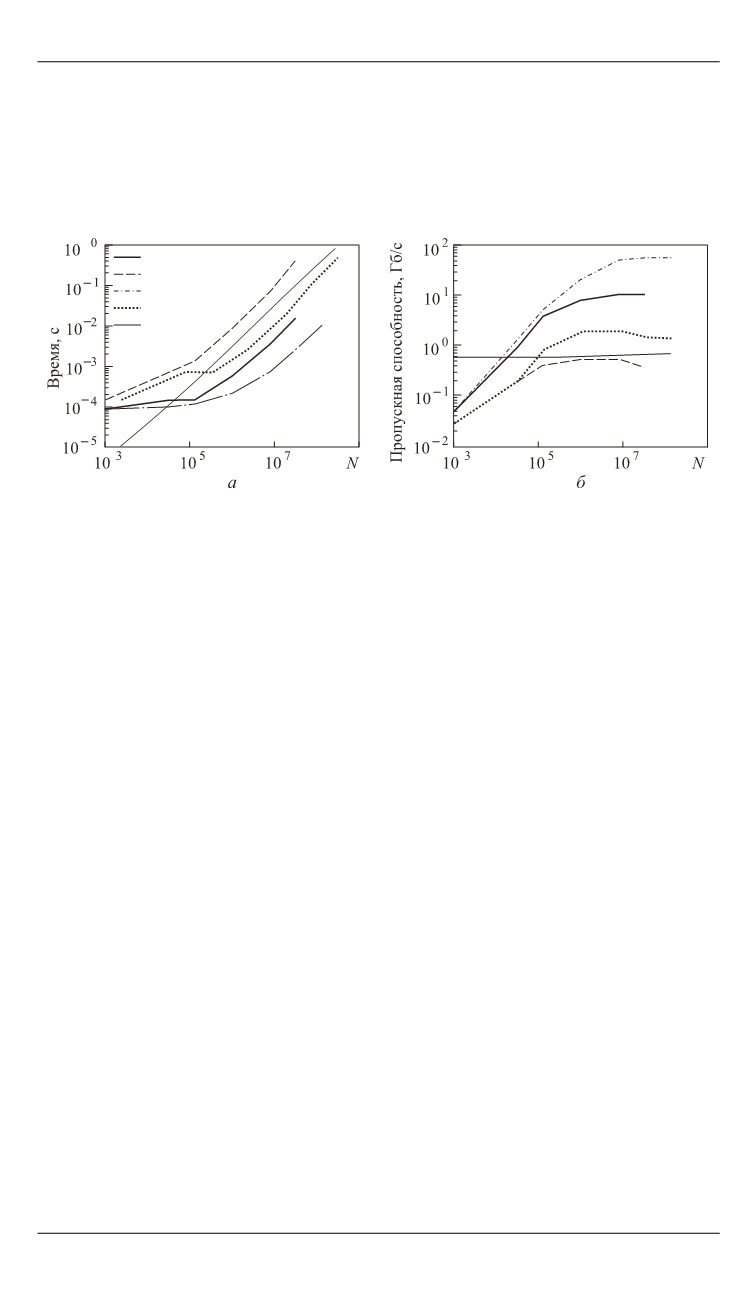
Время выполнения алгоритма на
CPU
линейно зависит от
N
,
что подтверждает сложность алгоритма последовательной агрега-
ции данных
O(N)
(рис. 6). Следовательно, пропускная способность
процессора
CPU
, рассчитанная по формуле (11), имеет постоянное
значение.
Рис. 6.
Сравнение времени выполнения алгоритма (
а
) и пропускной
способности (
б
) в зависимости от количества отсчетов входных данных
Время выполнения алгоритма на
GPU
имеет более сложную
зависимость от
N
, что подтверждает постепенное изменение слож-
ности алгоритма параллельной агрегации данных от
O
(log(
N
))
до
O
(
N
log(
N
))
в зависимости от количества параллельных блоков по-
токов, запускаемых одновременно. Так, до некоторого порогового
значения
N
~10
5
время выполнения алгоритма практически посто-
янно, так как у
GPU
есть ресурсы для запуска небольшого количе-
ства потоков одновременно. Далее время выполнения стремится к
линейной зависимости, а пропускная способность — к пиковому
значению. Следует также заметить, что целесообразность приме-
нения параллельного алгоритма возникает только при
N
> 10
4
.
Для исследования возможностей эффективного масштабирования
и навигации по данным использовались аудиосигналы длительно-
стью 47 и 243 мин (рис. 7).
Заключение.
В настоящей работе исследован метод визуализа-
ции данных большого объема, таких как данные о вербальном и не-
вербальном поведении человека. Разработаны модели визуализации
данных с учетом возможности их масштабирования и перемещения
по графикам, а также алгоритм параллельной агрегации данных, за-
ключающийся в нахождении экстремумов их блоков. На основе
предложенной модели и алгоритма создано программное обеспече-
ние, позволяющее проводить исследование эффективности названно-
го алгоритма.


